
The Apache Modeling Project. Глава 4 (Часть 3)
Предыдущая статья: The Apache Modeling Project. Глава 4 (Часть 2)
4.4 Цикл ‘запрос-ответ’
4.4.1 Обзор
Цикл ‘запрос-ответ’ является сердцем HTTP сервера. Каждый дочерний сервер Apache находится в этом цикле до тех пор, пока не завершится или пока не будет завершен главным сервером, либо в случае замены его поколения серверов более новым.
Рисунок 4.13 изображает цикл ‘запрос-ответ’ и цикле keep-alive. Если быть более точным, то цикл ‘запрос-ответ’ работает с запросами на соединения, а цикл keep-alive предназначен для получения и отправки HTTP запросов на это соединение.
4.4.2 Ожидание запросов на соединение
В зависимости от используемой многозадачной архитектуры, либо каждый свободный рабочий пытается стать прослушивателем, либо он получает запросы из очереди заданий. В обоих случаях он будет приостановлен до тех пор, пока не станет доступен семафор или пока в очереди заданий не появиться новое задание.
Переходы в прямоугольнике “Ожидание TCP запроса” на рисунке 4.13 изображают модель ‘Лидер - последователи’ МП-модуля prefork: Задача дочернего сервера - получить разрешающий семафор, чтобы стать прослушивателем, и он будет приостановлен, пока не получит TCP соединение. После того как он примет соединение, он освободит разрешающий семафор (см. также child_main() в prefork.c).
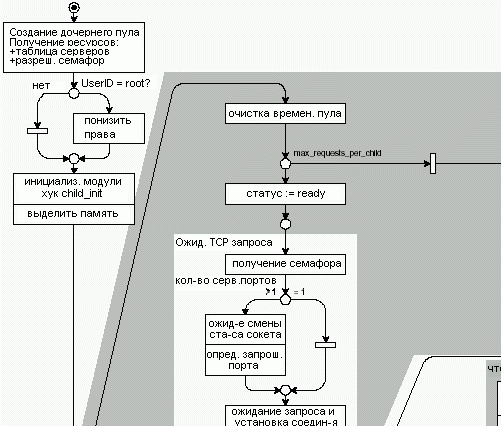
После того как дочерний сервер получит запрос на соединение, он покидает область влияния МП-модуля и вызывает срабатывание хуков pre_connection и process_connection. Программный модуль http_core.c регистрирует обработчик ap_process_http_connection() для последнего хука, который читает и обрабатывает запрос.
4.4.3 Ожидание и чтение HTTP запросов
HTTP клиент, например браузер, использует одно TCP соединение для некоторой последовательности запросов. HTML документ с пятью картинками требует последовательности из 6 HTTP запросов, которые могут использовать одно TCP соединение. TCP соединение закрывается после завершения периода тайм-аута (обычно 15 секунд). Так как HTTP заголовок, используемый для контроля соединения, имеет значение “keep-alive”, поэтому цикл носит такое же название.
Цикл keep-alive предназначен для чтения и обработки HTTP запросов. В Apache 2.0 модуль http_core.c регистрирует обработчик ap_process_http_connection(), который и содержит цикл keep-alive. Пул запроса, подобно временному пулу, очищается всякий раз при запуске цикла keep-alive.
Дочерний сервер читает заголовки запроса (тело запроса будет обработано соответствующим обработчиком контента) с помощью процедуры ap_read_request(), находящейся в protocol.c Результат обработки он хранит в структуре request_rec. В данной фазе обработки могут произойти множество ошибок. Поэтому важно, чтобы в это время читались только заголовки HTTP запроса.
4.4.4 Обработка HTTP запроса
После того, как HTTP заголовки будут прочитаны, статус дочернего сервера меняется на “busy_write”. Теперь наступает фаза ответа на запрос.
Рисунок 4.14 показывает детали обработки запроса в Apache 2.0. Обработка запросов в Apache 1.3. происходит почти таким же образом. Кроме одного главного исключения - в Apache 1.3 может использоваться только единственный обработчик контента, в то время как в Apache 2.0 в формировании ответа могут принять участие множество модулей (концепция фильтров).
Процедура ap_process_request() в http_request.c вызывает функцию process_request_internal(), находящуюся в request.c. То, что происходит в этой процедуре, показано на рисунке 4.14, который похож на рисунок 3.9, но предоставляет технические детали и объяснения:
- Сперва модифицируется URI (ap_unescape_URL(), ap_getparents()): Apache заменяет последовательностью эскейп-символов наподобие “%20″ и лишние пути наподобие “./xxx” или “xxx/../”.
- Затем Apache получает конфигурацию на запрошенный URI: location_walk(). Это происходит перед модулем преобразования URI, потому что он может повлиять на путь преобразования URI. Более детальную информацию об управлении конфигурацией Apache можно найти в разделе 4.5.
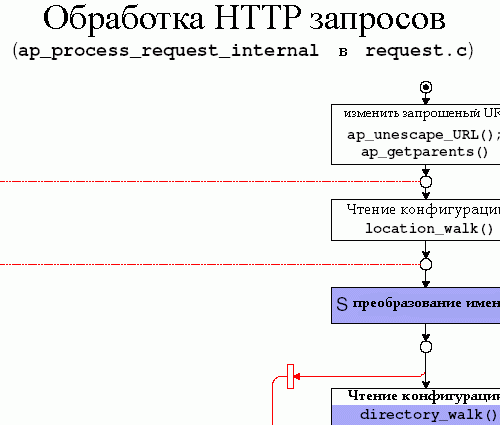
- ap_translate_name(): Некоторые модульные обработчики должны преобразовывать запрошенный URI в локальное имя ресурса, обычно в путь файловой системы.
- Новое получение конфигурационных данных для запрошенного URI с помощью процедуры location_walk() (полученный URI может отличаться от запрошенного URI после того, как будет обработан с помощью ap_translatate_name()!). Обработчик для хука map_to_storage - core_map_to_storage() вызывает ap_directory_walk() и ap_file_walk(), которые собирают и объединяют конфигурационные данные для пути и имени запрошенного файла. Результатом является конфигурация, которая будет передана всем модульным обработчикам, обрабатывающим этот запрос.
(”walk”: Apache обходит данные конфигурации для каждого уровня пути, начиная от корня. Файлы .htaccess читаются процедурой directory_walk() в каждой директории и с помощью процедуры file_walk() в крайних директориях) - header_parser: Каждый модуль имеет возможность обработать заголовки
Проверка авторизации
Существуют две независимые проверки авторизации:
- Проверка доступа, основанная на IP адресе клиентского компьютера.
- Проверка авторизации, основанная на идентификации пользователя.
Администратор может сконфигурировать для каждого ресурса:
- Пользователей, группы, IP адреса и адреса сетей.
- Правила для проверки авторизации (допуск/запрет IP или пользователя).
Сложное функционирование механизма авторизации не может быть полностью показано на рисунке 4.14. Используйте матрицу с левой стороны рисунка для сопоставления программных блоков операциям авторизации.
- access_checker: авторизация, основанная на IP.
- ap_check_user_id: проверка аутентификации.
- auth_checker: авторизация, основанная на проверке пользователя.
- type_checker: получение MIME-типа для запрошенного ресурса. Это важно для выбора соответствующего обработчика контента.
- fixups: любой модуль может писать данные в заголовки ответа.
- insert_filter: любой модуль может зарегистрировать выходной фильтры.
- handler: модуль регистрирует для MIME-типа ресурса один или более обработчиков контента. Некоторые обработчики, например обработчик контента CGI модуля, также читают тело запроса. Обработчик контента отсылает тело ответа через цепочку выходных фильтров.
- ap_finalize_request_protocol(): Этот метод следует назвать “завершение ответа”. Его единственная цель - это отправлять завершающую информацию, предусмотренную протоколом, для любого сообщения.
Обработка ошибок показана на левой стороне. Процедура ap_die() проверяет статус и при обнаружении ошибки, отправляет сообщение о ней.
Для дополнительной информации о фильтрах, см. раздел 3.3.4
4.5 Обработчик конфигурации
4.5.1 Где и когда Apache читает конфигурацию
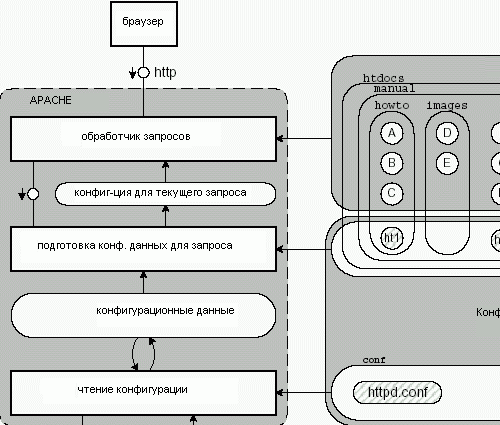
После сборки сервера Apache, администратор может сконфигурировать его при запуске через параметры командной строки или через глобальные файлы конфигурации. Локальные файлы конфигурации (обычно названные .htaccess) обрабатываются при каждом запросе и могут быть изменены пользователями каталогов.
Рисунок 4.15 показывает структуру сервера Apache с точки зрения обработки конфигурации. Внизу, мы видим администратора, изменяющего глобальные конфигурационные файлы, такие как: httpd.conf, srm.conf, access.conf и локальные конфигурационные файлы: ht1 до ht5 (.htaccess). Администратор запускает Apache, передавая ему параметры командной строки. Затем обработчик конфигурации считывает и обрабатывает файлы глобальной конфигурации и параметры командной строки. После этого он сохраняет результаты в хранилище данных конфигурации, которое содержит все данные внутренней конфигурации.
Для каждого запроса приходящего от браузера, обработчик контента запрашивает сгенерировать для него конфигурационные данные. Генератор конфигурации обрабатывает файлы .htaccess, которые он найдет по пути к ресурсу, и объединяет их с уже обработанными данными. На данный момент обработчик запроса знает как преобразовать запрошенный URI, и он определил, авторизирован ли клиент для получения этого ресурса.
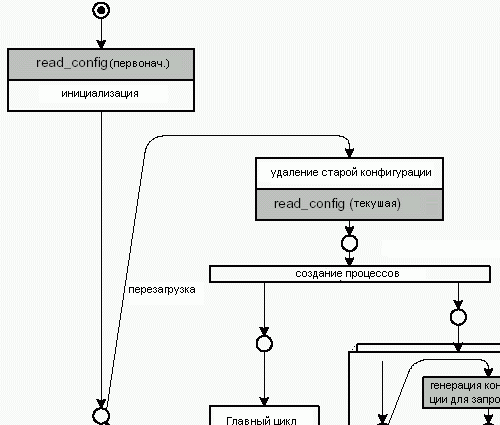
Рисунок 4.16 показывает моменты времени, когда Apache обрабатывает конфигурацию - диаграмма является частью рисунка 4.7. После того, как главный сервер считает конфигурацию, он входит в цикл перезагрузки. Каждый раз при перезагрузке он удаляет старую конфигурацию и заново обрабатывает главный файл конфигурации.
В цикле ‘запрос-ответ’, дочерний сервер генерирует конфигурацию для каждого запроса. Так как конфигурационные данные запроса находятся в структуре request_rec, поэтому после обработки запроса она удаляется.
В следующих частях, мы рассмотрим структуры данных, которые создаются при обработке глобальных файлов конфигурации. После этого мы взглянем на исходный код, отвечающий за это. Затем мы опишем процесс обработки данных конфигурации запроса.
4.5.2 Внутренние структуры данных
Мы рассмотрим внутренние структуры данных конфигурации, используя рисунок 4.17, который дает обзор структур в виде диаграммы сущность-связь, и используя рисунок 4.18, который показывает пример структуры в модуле mod_so.
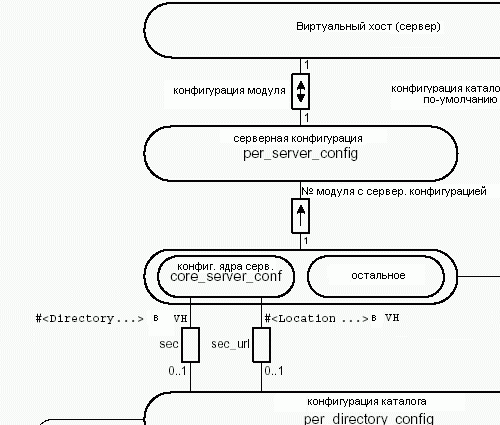
Каждый виртуальный хост имеет одну структуру per_server_config, содержащую серверную информацию и одну per_directory_config, содержащую дефолтовую конфигурацию каталога (lookup_defaults). Структуры per_server_config и per_directory_config реализованы в виде указателей на массивы указателей.
Для каждого модуля массив per_server_config содержит запись. Запись для модуля ядра (core_server_conf) имеет указатели на per_directory_config для каждой директивы Directory и Location, найденной в файлах конфигурации.
Каждый массив per_directory_config вновь содержит запись для каждого модуля. Запись для модуля ядра (core_per_dir_config) также имеет per_directory_config для каждой директивы Files, найденной в файлах конфигурации.
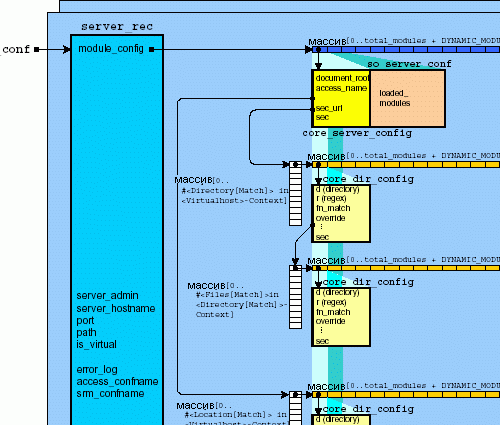
Рисунок 4.18 показывает структуру данных, сгенерированных модулем ядра для каждого виртуального хоста. Указатель server_conf указывает на текущий виртуальный сервер, найденный при просмотре списка хостов через next-указатели в server_recs. Структура также содержит другие серверные структуры: server_admin, server_hostname и указатели на структуры module_config и lookup_defaults.
Оба указывают на массив, чей размер равен общему количеству модулей, плюс количество динамически загружаемых модулей, то есть по одной записи для каждого модуля. Каждое поле массива ссылается на структуру данных, определенную соответствующим модулем.
На рисунке 4.18 показаны структуры данных модуля ядра и модуля mod_so. Диаграмма детально показывает структуры данных модуля ядра, так как этот модуль является самым важным для всей конфигурации Apache и содержит: document_root, access_name, sec_url и sec.
Указатель sec указывает на массив, состоящий из указателей - по одному указателю для каждой директории, найденной в конфигурационных файлах и отсортированных по числу слешей в пути, от минимального до самого длинного. Каждый из них в свою очередь ссылается на массив, который содержит по записи для каждого модуля. Поэтому command_handlers каждого модуля имеют возможность создавать структуры данных и работать с данными в соответствующих секциях для каждой директории (через обработчики конфигурации каталогов). Структура данных модуля ядра для каждого каталога также содержит указатель sec на структуры данных подобным ранее, но уже для файловых секций.
Ниже указателя sec в структуре данных модуля ядра содержится указатель sec_url. Он также указывает на, подобную указателю sec, структуру, но для директив Location в файлах конфигурации.
Таким образом, каждый модуль получает возможность создать собственную структуру данных для каждой директивы каталога (Directiry), файла (File) и URL (Location). Обработчики конфигурации каталогов также отвечают за записи соответствующих секций файлов и URL.
Структура данных, на которую указывает lookup_defaults, тоже указывает на структуру, подобную рассмотренной выше. Однако ее указатель sec указывает только на массив файловых секций. Так сделано, потому что эта структура содержит данные файловых секций, которые переопределены в контексте данного каталога.
Также внизу диаграммы изображена структура command_rec, содержащая некоторые директивы ядра и модуля mod_so.
4.5.3 Обработка данных конфигурации при запуске
При запуске Apache обрабатывает главные файлы конфигурации дважды (см. рисунок 4.16). Первый проход необходим для проверки синтаксиса главного файла конфигурации (параметр командной строки -t). Второй проход необходим, так как серверу необходима актуальная конфигурация после каждой перезагрузки.
При запуске или перезагрузке Apache вызывает функцию ap_read_config() для обработки конфигурации. Функция первый раз вызывается в main(), а затем в цикле перезагрузки.
Обработка глобальных данных конфигурации
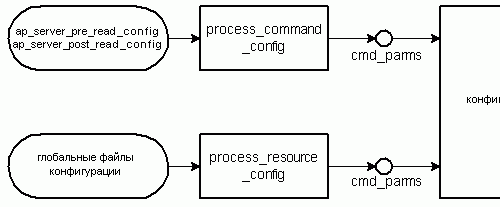
Рисунок 4.19 показывает поток данных в обработчике глобальной конфигурации:
агент process_command_config отвечает за чтение параметров командной строки из структур ap_server_per_read_config и ap_server_post_read_config, а агент process_resource_config читает файлы глобальной конфигурации. Оба агента передают свои данные обработчику конфигурационных файлов (ap_srm_command_loop). Это сердце обработки конфигурации, которое назначает обработку директив соответствующим командным обработчикам модулей.
агент process_command_config отвечает за чтение параметров командной строки из структур ap_server_per_read_config и ap_server_post_read_config, а агент process_resource_config читает файлы глобальной конфигурации. Оба агента передают свои данные обработчику конфигурационных файлов (ap_srm_command_loop). Это сердце обработки конфигурации, которое назначает обработку директив соответствующим командным обработчикам модулей.
Рисунок 4.20 показывает вызовы функций относительно конфигурации.
[Примечание: рассмотрены только наиболее важные процедуры]
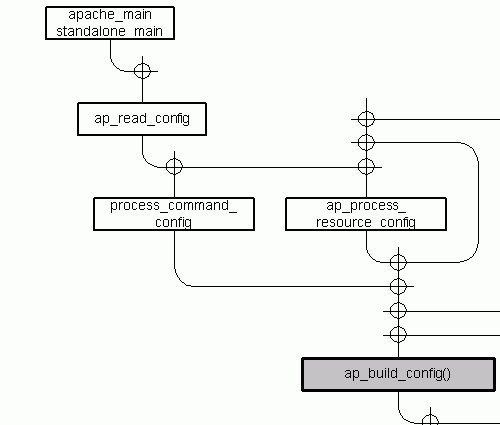
ap_read_config() вызывает процедуры process_command_config() и ap_process_resource_config().
process_command_config() обрабатывает директивы, которые передаются Apache через командную строку (параметры командной строки -с или -С). Аргументы командной строки читаются в main() и сохраняются в массивах ap_server_pre_read_config и ap_server_post_read_config в зависимости от того, должны ли они быть обработаны перед или после главного файла конфигурации. Эти массивы обрабатываются как файлы конфигурации и передаются функции ap_build_config() (ap_srm_command_loop() в Apache 1.3) через структуру данных cmd_parms, которая содержит дополнительную информацию, как, например, текущий сервер, указатели на память (пулы) и переопределенную информацию (см. также рисунок 4.20).
ap_process_resource_config() фактически обрабатывает главный файл конфигурации. Apache имеет возможность обработать структуру каталогов, если вместо имени файла было дано имя каталога. Функция вызывает себя рекурсивно для каждого каталога и тем самым обрабатывает всю структуру каталогов. Для каждого файла, найденного в конце рекурсии структура cmd_parms хранит указатель, который затем передается в ap_build_config() (ap_srm_command_loop() в Apache 1.3).
Обработка директив
Процедура ap_build_config() (ap_srm_command_loop() в Apache 1.3) обрабатывает директивы в конфигурационном файле построчно. Для этого используется функция ap_cfg_get_line() (ap_cfg_get_line() в Apache 1.3), которая возвращает одну обработанную строку файла конфигурации, удаляя передние и задние пробелы, обратные слешы, переводы строк и т.п.
После этого строка передается функции ap_build_config_sub() (ap_handle_command() в Apache 1.3), которая в случае, если строка пустая или является комментарием, ничего не делает. Если строка содержит директиву, то функция использует ap_find_command_in_modules() (ap_find_command_in_modules соответственно) для поиска первого модуля в списке модулей, который может обработать эту команду. Возвращенная структура command_rec (для получения доп. информации о структуре command_rec см. раздел 3.3) передается процедуре execute_now(), которая в свою очередь выполняет invoke_cmd() (invoke_cmd в Apache 1.3). Если execute_now() (или invoke_cmd()) возвращает DECLINED, то ap_find_command_in_modules() вызывается еще раз, чтобы получить command_rec от следующего модуля, который может обработать команду.
Процедура invoke_cmd() фактически вызывает функцию модуля через указатель на нее. В зависимости от данных в command_rec, считывается определенное число аргументов (ap_get_word_conf в Apache 2.0 или ap_get_word_conf в Apache 1.3) и передается вызываемой функции, так же передается cmd_parms и module_config. Структура cmd_parms содержит данные о том, где обработчик может хранить свои конфигурационные данные.
Обработка секций каталогов, файлов и URL
Рисунок 4.20 показывает обработчики директив (ссылки в скобках показывают версию функции для Apache 1.3):
dirsection (dirsection), filesection (filesection) и urlsection (urlsection) функции соответственно для директив <Directory>, <Files> и <Location>. И вновь они используют ap_build_config() (ap_srm_command_loop()) для обработки директив внутри секции.
Например, посмотрим как Apache обрабатывает директиву <Directory>, вызывая командный обработчик dirsection(). Это можно увидеть на рисунке 4.21. Сейчас dirsection() вызывает ap_build_config() (ap_srm_command_loop()) для обработки построчно всех директив внутри этой секции.
Если Apache определяет директиву </Directory>, он вызовет соответствующий обработчик команды, который вернет найденную строку </Directory> в качестве сообщения об ошибке, в результате чего обработка строк остановится и ap_build_config() (ap_srm_command_loop()) вернет управление. Если он вернул NULL, то это означает, что он закончил обработку файла конфигурации и не обнаружил соответствующий, закрывающий секцию, тег. Вследствие чего, вызов функции dirsection() возвращает ошибку “missing end section”.
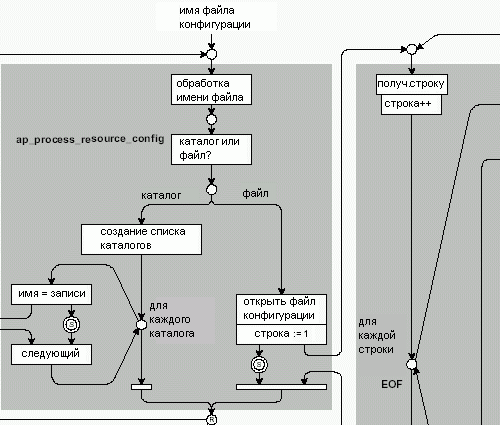
Директивы <VirtualHost> тоже работают подобным образом. Для директивы Include снова вызывается процедура ap_process_resource_config(), которая обрабатывает включаемый файл конфигурации.
4.5.4 Обработка данных конфигурации при запросах
Используемые структуры данных
Apache считывает данные конфигурации при запуске и хранит их во внутренних структурах данных. Всякий раз, когда дочерний сервер обрабатывает запрос, он получает данные конфигурации и объединяет их с данными, полученными из файлов .htaccess, чтобы получить соответствующую полную конфигурацию для текущего запроса.
Рисунок 4.22 показывает строение обработчика конфигурации и структуры данных, используемые для хранения данных конфигурации для одного виртуального хоста. Эти структуры данных создаются при запуске и детально показаны на рисунках 4.17 и 4.18. Здесь изображены структуры sec, sec_url, server_rec и lookup_defaults. Имена файлов, которые будут обработаны при запросе, также хранятся в структуре core_server_config и по умолчанию имеют значения .htaccess. Конфигурация для запроса сохраняется в структуре request_rec, которая изображена на правой стороне диаграммы, также она содержит необходимую информацию для функций обхода.
Вызываемые функции
Дочерний сервер для обработки запроса вызывает функцию process_request_internal(). Она первая получает конфигурацию для запрошенного URI, вызывая процедуру location_walk() и передавая request_rec в качестве параметра. Это делается до того, как обработчик модуля получит возможность преобразовать URI запроса (ap_translate_name()), потому что он может повлиять на это преобразование.
После преобразования URI запроса, дочерний сервер вызывает три функции обхода в следующем порядке: директории, файлы и URI (см. рисунок 4.14).
Процедуры обхода
Процедура directory_walk() очищает структуру per_dir_config, таким образом, первый обход перед преобразованием URI не влияет на дальнейшую обработку.
Все процедуры обхода работают одинаково. Они обходят список секций, который хранится в соответствующих структурах данных, и проверяют на совпадение названий секций директорий, файлов и URI.
Тем не менее, обход директорий более сложен и поэтому будет рассмотрен более подробно.
Обход директорий происходит вниз по иерархии директорий, в поиске имен, которые совпадают с именем в request_rec, объединяя соответствующие данные в per_dir_config структуры request_rec (используя ap_merger_per_dir_configs()).
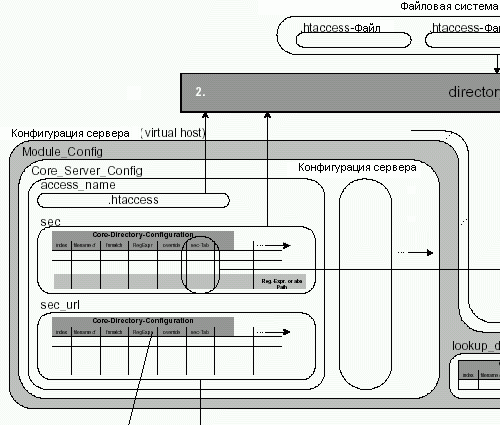
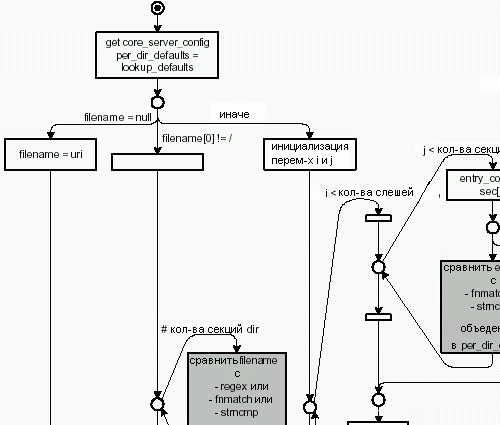
Рисунок 4.23 показывает, что происходит в процессе обхода каталогов (обработка ошибок не рассматривается):
Сперва, структура lookup_defaults связывается со структурой per_dir_defaults и затем берется в качестве основы для дальнейшей обработки. Позже, все совпадающие каталоги объединятся в per_dir_defaults (в пуле request_rec).
В основном существуют три пути обхода каталогов, которые выбираются в зависимости от filename.
- Пропуск пути, если они не содержат данный filename и установка URI в качестве filename.
- Второй путь выбирается, если filename не начинается с символа ‘/’. В этом случае, происходит обход секций каталогов, и filename сравнивается с именами каталогов.
Для сравнения используется либо fnmatch, либо функция, специфицированная в POSIX, регулярное выражение или просто сравнение строк.
Обходится массив вхождений и проверяется, совпадает ли имя секции, и в случае совпадения объединяется в структуре per_dir_defaults. - Третий путь использует вложенные циклы. Здесь, важен порядок вхождений (см. ap_core_reorder_directories() в http_core.c). Секции каталогов упорядочиваются в следующем порядке: однокомпонентные секции идут первыми, затем идут секции, состоящие из двух компонентов и т.д, и завершается все ‘специальными’ секциями. Секция называется ‘специальной’, если она является regexp (регулярным выражением) или она не начинается с символа ‘/’.
Внешний цикл обходит вхождения, запоминая их позиции в переменной j. Если текущая позиция является регулярным выражением и каталог не начинается с символа ‘/’, что означает вхождение в специальную секцию, то внутренний и внешний цикл завершается. Регулярные выражения сравниваются позже в отдельном цикле.Если внутренний цикл прерывается по причине того, что количество слешей в имени каталога больше чем i, то вхождение пропускается и включается файл .htaccess соответствующего каталога. Затем внешний цикл начинает новый виток. Таким образом, включаются все необходимые .htaccess файлы.
Если не произошло остановок, то мы в нужном месте. Во внутреннем цикле имя каталога сравнивается с помощью функции fnmatch или strncmp. В случае совпадения результат объединяется со значением per_dir_defaults.
Если файл .htaccess имеет права на перезапись, то применяется переопределение данных.
Если файл .htaccess необходимо обработать, то вызывается процедура ap_parse_htaccess(). Эта процедура в свою очередь вызывает ap_build_config() (см. рисунок 4.20), которая работает также как и при запуске для главных файлов конфигурации, но в этот раз для per_dir_config структуры request_rec.
file_walk() работает только для per_dir_config структуры request_rec, так как структуры для файловых директив уже скопированы из core_server_config и lookup_defaults в per_dir_config структуры request_rec при обходе каталогов. Filename файла для поиска находиться в request_rec.
location_walk() использует sec_url и URI, находящиеся в request_rec. Как и другие функции обхода, она проходит вхождения соответствующей структуры данных (sec_url) и объединяет совпадающие вхождения в структуре request_rec.
4.6 Управление ресурсами и памятью: Пулы Apache
Apache предоставляет свое собственное управление памятью и ресурсами, известное как пулы. Пулы предназначены для хранения всех ресурсов, используемых Apache для себя или для любого модуля, используемого вместе с Apache. Пул может управлять памятью, сокетами и процессами, которые являются важными ресурсами для сервера.
4.6.1 Зачем нужно другое управление памятью?
В основном пулы используются для снижения вероятности ошибок программирования. В любой С программе необходимо выделять память. Если программа потеряет ссылки на такую память, (без пометки ее как освобожденной для использования другой программой) она становится недоступной до тех пор, пока не завершится программа. Это называется утечка памяти. В программах, в основном используемых в клиентском окружении, это не приносит большого вреда, так как они обычно не работают долго, а по завершению работы, операционная система сама освобождает всю занимаемую память. Другое дело серверное окружение - серверное приложение обычно функционирует долго. Даже небольшая утечка в повторяющемся цикле может привести к аварийному завершению работы сервера.
Сокеты также ограничены. Если программа регистрирует сокет и не освобождает его после завершения работы с ним, то ни одна другая программа не сможет использовать его. Сокеты также используют другие ресурсы, такие как память и CPU. Если часть серверной программы, которая повторно выполняется, регистрирует сокеты и не освобождает их, сервер неизбежно упадет. Множество серверов работают с многонитеевой архитектурой, что означает, что более чем один процесс или нить запущены во время работы сервера. Обычно эти процессы завершаются только администратором. Если программа запускает такие ‘незавершающиеся’ процессы циклично и забывает их завершать, то серверные ресурсы быстро достигнут предела и сервер упадет.
В концепции пулов разработчик регистрирует любую память, сокеты или процессы в пуле, который имеет предопределенный период жизни. Когда уничтожается пул, все ресурсы, управляемые этим пулом, автоматически высвобождаются. Только несколько функций, которые тщательно протестированы, выполняют освобождение ресурсов, зарегистрированных для этого пула. Таким образом, необходимо только несколько функций, чтобы быть уверенным, что все ресурсы будут освобождены. Ошибки внутри их гораздо легче найти и данная концепция сняла это бремя с разработчиков.
Также механизм пулов повышает производительность. Обычно программы используют блок памяти один раз, и затем освобождает его. Это требует много дополнительной работы, так как системе требуется выделить, освободить и отобразить из виртуальной памяти этот блок. Если используется большое число небольших блоков памяти, то это может привести к существенному снижению производительности. Также, операционная система обычно выделяет не меньше определенного числа байт, вне зависимости от того, сколько памяти было запрошено. Такой подход приводит к потере маленьких блоков памяти. И если такое происходит слишком часто, то общий объем потерянной памяти станет существенным.
4.6.2 Структура пулов
Встроенные пулы и периоды их жизни

Apache имеет различные встроенные пулы, каждый из которых имеет собственное время жизни. Рисунок 4.24 показывает иерархию пулов. Пул pglobal существует весь период работы сервера. Пул pchild имеет время жизни дочернего сервера. Пул pconn связывается с каждым соединением, а пул preq с каждым запросом. Обычно разработчику следует использовать пул с минимально необходимым периодом жизни для хранения данных, чтобы минимизировать использование ресурсов.
Если разработчику требуется большее количество памяти или других ресурсов, и он не может найти пул с соответствующим периодом жизни, то он может создать подпул любого существующего пула. Затем он может использовать этот пул, как и любой другой, и может уничтожить его, когда он перестанет быть нужным. Если программист забыл уничтожить этот пул, он будет автоматически уничтожен, когда Apache уничтожит его родительский пул. Все пулы являются подпулами главного пула сервера - pglobal. Пул соединения, являющийся подпулом дочернего сервера, обслуживает это соединение, а все пулы запросов являются подпулами соответствующих пулов соединений.
Внутренняя структура
Внутренне пул организован как связный список подпулов, блоков, процессов и callback-функций. Рисунок 4.25 дает изображение блока и пример связного списка блоков.
Если необходима память, она выделяется с помощью предопределенных функций. Эти функции не только выделяют память, но также заботятся о сохранении ссылок, чтобы эту память можно было впоследствии высвободить. Также подобным образом в пуле могут быть зарегистрированы процессы, чтобы уничтожиться после смерти пула. Вдобавок каждый пул может содержать информацию о функциях, которые необходимо вызывать перед освобождением памяти. Таким образом, при уничтожении пула можно освободить файлы и сокеты.

Завершающая последовательность
После того как пул уничтожается, Apache первым делом вызывает все зарегистрированные функции очистки. Таким образом, закрываются все зарегистрированные открытые файлы и сокеты. Затем пул начинает завершать все зарегистрированные и запущенные процессы. И, напоследок, освобождаются все блоки памяти. Обычно Apache по настоящему не освобождает память, а удаляет ее из пула и добавляет в список свободной памяти, который хранится внутри ядра сервера. Такой подход позволяет свести к минимуму количество выделений и освобождений памяти. Ядро всегда доступно для получения выделенной памяти. Новую память необходимо выделить, только если требуется больше памяти, чем раньше было освобождено.
Блоки и производительность
Apache выделяет один блок памяти за раз. Блок обычно гораздо больше, чем запрошено модулем. Так как блок всегда принадлежит одному пулу, то он связывается с пулом один раз. Последующие запросы памяти удовлетворяются за счет памяти, оставшейся в этом пуле. Если запрошено больше памяти, чем осталось в последнем блоке, в цепочку добавляется новый блок. А память, оставшуюся в предыдущем блоке не используется до тех пор, пока пулы не будут уничтожены, и блок не добавится в список свободных блоков.
Так как блоки не освобождаются, а добавляются в список свободных блоков, Apache необходимо выделить новые блоки только один раз. Такой подход позволяет существенно сократить траты ресурсов системы на выделение памяти. При данных обстоятельствах, количество памяти, используемое для хранения аналогичного количества информации, больше по сравнению с обычным выделением памяти, так как Apache всегда выделяет больший объем, чем нужно. Размер блока может быть изменен в конфигурации Apache.
4.6.3 API пулов
Так как каждый пул выполняет очистку ресурсов, зарегистрированных в нем, то существуют API функции для выделения ресурсов и регистрации их в пуле. Тем не менее, некоторые ресурсы могут быть удалены вручную перед уничтожением пула.
Выделение памяти
Когда выделяется память, разработчики могут использовать две различные функции: ap_palloc и ap_pcalloc. Обе получают в качестве аргументов пул и размер требуемой памяти и возвращают указатель на память, зарегистрированную и доступную к использованию. Отличие заключаются в том, что ap_pcalloc очищает память перед возвратом указателя.
Функция ap_strdup используется для выделения памяти из пула и размещения копии строки в ней, которая передается функции в качестве аргумента. ap_strcat используется для инициализации новой строки при объединении всех строк перееденных в качестве аргументов.
Регистрация callback-функций
Почти все ресурсы могут быть зарегистрированы в пуле с использованием callback-функций. Эти функции вызываются, чтобы освободить зарегистрированный ресурс перед уничтожением пула. Такой подход позволяет использовать любой тип ресурсов в механизме пулов.
Для файловых дескрипторов и сокетов ядро сервера предоставляет эквиваленты команд fopen и fclose() (для файлов). Они требуют регистрации callback-функций. Они регистрируют функцию, которая может быть вызвана для закрытия файлового дескриптора, когда пул будет уничтожен.
Управление процессами
Также пул может управлять процессами. Они регистрируются в пуле, используя функцию ap_note_subprocess (если процесс уже создан). Наилучший путь - это использовать функцию ap_spawn_child, так как она также регистрирует в пуле все каналы и другие ресурсы, необходимые процессу.
Подпулы
Подпулы требуются в том случае, если созданный пул не подходит для задачи, которая возможно требует большее количество памяти на некоторое время. Подпулы создаются, используя функцию ap_make_sub_pool. В качестве аргумента она требует родительский пул, а возвращает созданный. Теперь этот пул может быть использован для выделения ресурсов относительно независимых от родительского пула. Преимущества заключается в том, что этот пул может быть очищен (ap_clear_pool) или даже удален (ap_destroy_pool) без влияния на родительский пул. Тем не менее, когда родительский пул уничтожается, подпул также автоматически уничтожается.
















Комментарий от Егорыч — Сентябрь 1, 2008 @ 4:04 pm
Комментарий от Younger — Февраль 6, 2009 @ 2:41 pm